
개발하고 싶은 초심자
220325 D+67 AWS 본문
1. Cloud Computing
: 인터넷(클라우드)을 통해 서버, 스토리지, 데이터베이스 등의 컴퓨팅 서비스를 제공하는 서비스
⇒ 컴퓨터 통신망의 복잡한 네트워크 및 서버 구성 등을 알 필요 없이
어디에서나 컴퓨터 자원으로 인터넷이 연결된 어디서나 자신이 원하는 작업을 할 수 있다는 것을 보장해줌.
① 클라우드 컴퓨팅이 나오기 전 기존 서버 방식의 한계점
‣ 주기적인 유지관리 필요
‣ 공간의 한계
⇒ 추가적인 서버 증설이 어렵게 되어 데이터 센터의 등장, 유휴자원 대여 서비스 등장
⇒ 데이터 센터는 온프레미스 환경(서버의 자원과 공간 네트워크 환경 제공 환경)
② 클라우드
‣ 데이터 센터와 비슷한 역할을 하지만 가상화 기술의 발전으로부터 비롯된 가상 컴퓨터를 대여한다는 점이 다르다.
‣ 클라우드 서비스의 장점
→ 필요할 때마다 컴퓨팅 능력을 유연하게 조절 가능
→ 사용한 만큼의 요금만 지불하면 됨
→ 컴퓨터의 스냅샷(이미지)을 이용하여 다른 컴퓨터로 즉시 이주(migration) 가능
‣ 클라우드 환경의 단점
→ 운영 환경 자체가 클라우드 제공자(vendor)에게 종속되기 때문에
클라우드 서비스에 문제가 생기면 내가 배포하고 관리하는 환경에도 영향이 미친다.
⇒ 백엔드 구성 자체가 특정 회사의 기술로만 구성해야만 하는 경우가 발생할 수도 있다는 뜻이다.
‣ 클라우드는 모든 것을 서비스화하는 것을 목표로 한다(Everything as a Service)
• 대표적인 클라우드 서비스의 형태
⇒ 클라우드 제공자로부터 얼마만큼의 서비스를 제공받느냐에 따라 서비스의 형태가 구분된다.
→ SaaS(Software as a Service)
: 클라우드 제공자가 당장 사용 가능한 소프트웨어를 제공하는 경우 해당한다.
→IaaS(Infrastructure as a Service)
: 클라우드 제공자가 가상 컴퓨터까지 제공하는 경우 해당한다.
→PaaS(Platform as a Service)
: 클라우드 제공자가 데이터베이스, 개발 플랫폼까지 제공하는 경우 해당한다.
2. Deploy(배포)
: 개발한 서비스를 사용자가 이용 가능하게 하는 일련의 과정.
① 배포의 단계
‣ Deployment
: 각자의 컴퓨터(Local 컴퓨터 환경)에서 코드를 작성하고 테스트하는 과정
→ 개발 단계이기 때문에 실제 데이터가 아닌 더미 데이터(sample data)를 이용하여 테스트한다.
‣ Integration
: 각자의 컴퓨터에서 작성한 코드를 합치는 과정
→ 내가 작성한 코드가 다른 코드를 침범하여 오류를 일으키지는 않는지,
코드 간 conflict(충돌)가 있지 않은지 확인하는 과정을 거친다.
‣ Staging
: 실제 출시 단계인 Production 단계와 가장 유사한 환경에서 테스트를 진행한다.
→ 실제 데이터를 복사해서 문제가 있지 않은 지 등 다양한 환경에서 테스트를 진행한다.
→ 서비스와 관련된 부서 / 인원(모든 관계자들)의 확인 과정을 거친다.
(작성된 코드가 마케팅팀 / 디자인팀이 예상했던 결과인지 확인을 거치는 과정)
‣ Production
: 개발된 서비스를 출시하는 단계
→ 사용자가 접속할 수 있는 Production 단계에서 코드를 구동하고 서비스를 제공한다.
(개발환경과는 구분된 환경)
→ 실제 데이터를 이용하여 서비스가 제공되는 단계이므로 문제가 생기면 절대 안 됨.
⇒ Deployment 환경과 Production 환경은 서로 다를 수 있다.
혼자서 Development부터 Production 단계까지 모든 것을 통제할 수 있는 상황이라면 괜찮지만,
여러 명이 함께 작업하는 프로젝트라면
node 버전도 제각각일 거고, 인증 정보나 데이터베이스 등에 접근하기 위해 사용하는 엔드포인트도 제각각일 수 있다.
예를 들어, 내 로컬에 설치된 데이터베이스 비밀번호는 rlazheld1234! 인데,
클라우드에 설치된 데이터베이스 비밀번호는 supersecret! 일 수 있다.
이 모든 케이스를 코드 안에 담을 수는 없다.⇒ 환경의 차이를 이해하고 환경 설정을 코드와 분리하는 것이 중요하다.
② 작성한 코드가 다른 환경에서 정상 작동할 수 있게 하기 위한 방법
⇒ 환경 설정을 코드로부터 분리하는 방법론
‣ 절대경로 대신 상대경로를 사용한다.
‣ 설정을 환경변수(envvars / env)에 저장한다.
→ 환경에 따라 포트를 분기할 수 있도록 환경변수를 설정해준다.
→ 환경변수는 코드 변경 없이 배포 때마다 쉽게 변경할 수 있고,
설정 파일과 달리 잘못해서 코드 저장소에 올라갈 가능성도 낮다.
‣ Docker와 같은 가상화 도구는 환경 자체를 메타데이터로 담아 개발 환경을 모두 통일시키는 솔루션을 사용한다.
3. EC2(Elastic Compute Cloud)
: 아마존 웹 서비스(AWS)에서 제공하는 클라우드 컴퓨팅 서비스.
→ 비용적인 부분뿐만 아니라 필요에 따라 성능, 용량을 자유롭게 조절할 수 있다.
→ AWS에서 비용, 성능, 용량 면에서 탄력적인 클라우드 컴퓨터를 제공하는 서비스.
→ AWS에서 원격으로 제어할 수 있는 가상의 컴퓨터를 한 대 빌리는 것이므로
컴퓨터로 할 수 있는 모든 일을 할 수 있다.
⇒ 웹 서버를 설치하고 웹 서버를 통해 사용자가 웹 브라우저를 통해 요청하는 서비스 제공.
✷ AWS에서 빌리는 컴퓨터를 Instance, 즉 1대의 컴퓨터를 의미하는 단위이고
AWS에서 컴퓨터를 빌리는 것을 인스턴스를 생성한다고 한다.
① EC2 서비스 사용의 장점
‣ 구성하는 데 필요한 시간이 짧다.
‣ AMI를 통해 필요한 용도에 따라 다양한 운영체제에 대한 선택이 가능하다.
→ AMI라는 다양한 템플릿을 제공하고 있어 필요에 따라 손쉽게 운영체제를 선택하고 구성할 수 있으며,
CPU, RAM, 용량까지 손쉽게 구성할 수 있다.
② AMI(Amazon Machine Image)
: 소프트웨어 구성이 기재된 템플릿.
→ 이미지 종류로는 단순히 운영체제(윈도우, 우분투 리눅스 등)만 깔려있는 템플릿을 선택할 수도 있고,
아예 특정 런타임이 설치되어 있는 템플릿이 제공되는 경우도 있다. (우분투 + node.js, 윈도우 + JVM 등)
⇒ AWS에서 빌릴 PC는 사용 용도에 맞게 운영체제, 런타임 등이 구성된 setting을 선택할 수 있다.
⇒ 상당히 많은 양의 Image가 AWS에 미리 준비되어 있으며,
선택된 image를 바탕으로 Instance의 운영체제가 결정된다.
⇒ Instance는 선택한 AMI를 토대로 구성되며 세팅되어 있는 AMI 이외에 필요에 따라 직접 AMI 구성 가능.
③ EC2 Instance 생성의 의미

AMI를 토대로 운영체제, CPU, RAM, 런타임 등이 구성된, setting 된 컴퓨터(PC))를 빌리는 것이다.
4. RDS(Relational Database Service)
: AWS에서 제공하는 관계형 데이터베이스 서비스.
① RDS를 사용하는 이유
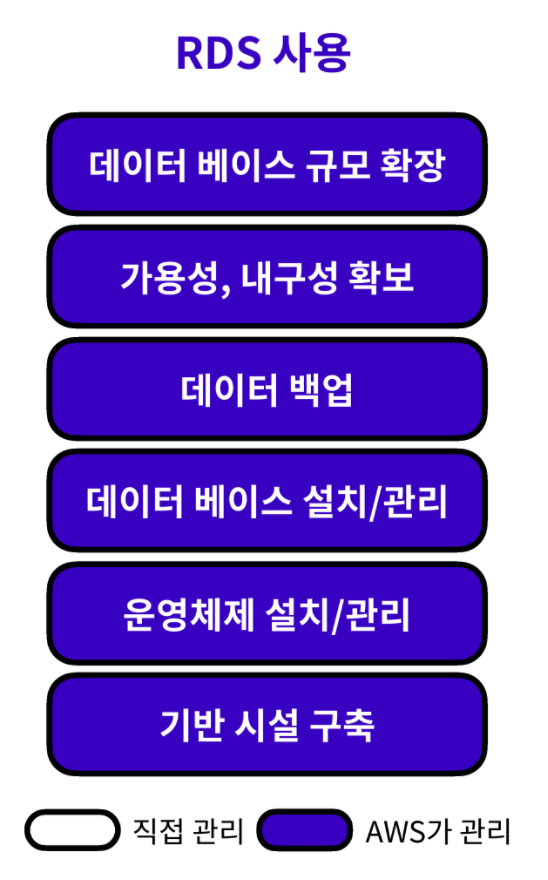
→ 데이터베이스 유지 보수와 관련된 일들을 전부 RDS에서 자동 관리한다.
→ 사용자가 해야 할 일은 초기 설정을 제외, 데이터베이스에 저장된 데이터를 관리하는 일 밖에 없기 때문에
큰 편의성을 느낄 수 있다.

반면 EC2 인스턴스에 데이터베이스를 직접 설치하여 데이터를 관리하면
데이터베이스와 관련하여 자동으로 관리를 담당하는 부분이 매우 적기 때문에
사용자가 일일이 데이터베이스 엔진의 설치와 버전 관리, 데이터 백업을 해야한다.
또한 가용성과 내구성이 확보되지 않기 때문에
데이터베이스에 저장된 데이터가 유실되거나 정상적으로 사용하지 못할 확률이 커지며,
나중에 필요에 따라 데이터베이스의 규모를 확장하기 어렵다.

→ RDS 이용 시 다양한 데이터베이스 엔진 선택지를 제공한다
⇒ 필요와 목적에 맞게 데이터베이스 엔진을 선택하여 효율성을 높일 수 있다.
5. S3(Simple Storage Service)
: AWS에서 제공하는 클라우드 스토리지 서비스
✷ 클라우드 스토리지 / 클라우드 스토리지가 갖는 장점
: 인터넷에 데이터를 저장하는 저장소.
(구글 드라이브, 네이버 마이박스, MS사의 원드라이브 서비스 등)
‣ 뛰어난 접근성을 가지고 있어 웹 환경이라면 언제 어디서나 저장된 파일에 접근할 수 있다.
‣ 컴퓨터 뿐만 아니라 웹에 접속이 가능한 다른 전자기기를 활용하여 클라우드 스토리지에 저장된 데이터에 접속할 수 있다.
① S3 사용 시 장점
‣ 높은 확장성.
→ 많은 시간과 수고를 들이지 않고 스토리지 규모를 확장 / 축소할 수 있다.
‣ 스토리지의 용량을 무한히 확장하여 사용한만큼 비용을 지불하면 되기 때문에
비용적 측면에서 매우 효율적이다.
‣ 강력한 내구성(99.999999999%의 내구성을 보장)
→ 저장된 파일을 유실할 가능성이 적어짐.
‣ 99.99%의 가용성 보장
→ 스토리지에 저장된 파일들을 정상적으로 사용할 수 있는 시간이 길어진다.
✷ AWS가 해당 서비스들의 높은 가용성과 내구성을 보장할 수 있는 원리

‣ Region(리전): AWS에서 클라우드 서비스를 제공하기 위해 운영하는 물리적인 서버의 위치
‣ Availability Zone(가용 영역): 각 리전 안에 존재하는 데이터 센터(IDC)
→ 각각 개별적인 위치에 떨어져 존재하기 때문에
한 곳의 가용 영역이 재난 / 사고로 인해 가동이 불가능해지더라도
다른 가용 영역에 백업 해놓은 데이터를 활용하여 문제없이 서버가 가동되게 한다.
→ 위 그림에서 주황색(리전을 의미)원 안에 써있는 숫자들이 가용 영역의 수.
‣ 다양한 스토리지 클래스 제공
→ 저장소를 어떤 목적으로 활용할지에 따라 효율적으로 선택할 수 있는 스토리지 클래스가 달라진다.
• Standard class
: 가장 일반적으로 사용되는 스토리지 클래스로 범용적인 목적으로 사용하기 좋다.
→ 데이터에 빠른 속도로 접근 가능, 데이터 액세스 요청에 대한 처리속도가 빠름
(데이터에 자주 액세스해야하는 경우에 사용함)
→ 보관 비용이 높게 발생하기 때문에 데이터를 오래 보관하는 목적으로는 비효율적임
• Glacier class
: 장기적인 보관 목적으로 사용할 때 효율적임
→ 저장된 데이터에 액세스하는 속도가 느림
→ 데이터를 보관하는 비용이 매우 저렴함.
⇒ 이 외에도 Standard-IA, One Zone-IA, S3 Glacier Deep Archive 등등
여러 가지 스토리지 클래스가 존재하여 사용자의 이용 목적에 따라 다양한 스토리지 클래스를 사용할 수 있다.
‣ 정적 웹 사이트 호스팅 가능
• 정적 파일: 서버의 개입 없이 생성된 파일
(동적 파일: 클라이언트가 서버에 요청을 보내면 서버가 요청에 맞춰 그 자리에서 생성한 파일)
• 웹 호스팅: 서버의 한 공간을 임대해주어 웹 사이트의 배포, 운영이 가능하게 만들어주는 서비스.
→ 개인 / 단체가 웹 호스팅 업체가 제공하는 서버의 한 공간을 빌려 원하는 서비스 배포 가능.
⇒ 버킷이라는 저장공간에 정적 파일을 업로드하고
버킷을 정적 웹 사이트 호스팅 용도로 구성하면 정적 웹 사이트 배포 가능.
✷ 버킷(bucket)
: 파일을 저장하는 최상위 디렉토리.
→ S3에서 저장되는 모든 파일은 버킷 안에 저장되어야 하고, 버킷에는 무한한 양의 파일을 저장할 수 있다.
→ 각각의 버킷은 이름을 가지고 있는데,
버킷의 이름은 버킷이 속해 있는 리전(버킷이 생성된 지역)에서 유일(고유)해야 한다.
→ 버킷 정책을 생성하여 해당 버킷에 대한 다른 유저의 접근 권한을 수정할 수 있다(액세스 권한 부여 가능).
✷ S3에서 저장소에 데이터를 저장할 때 키-값 페어 형식으로 데이터를 저장하기 때문에
버킷에 담기는 파일은 객체라고 부른다.
→ 객체는 파일과 메타 데이터로 구성된다.
→ 모든 객체는 고유한 키를 가진다.
→ 모든 객체는 고유한 URL 주소를 가지고 있어 이를 통해 객체에 접근이 가능하다.
http://버킷이름.S3.amazonaws.com/객체키
• 파일
: 키-값 페어 형식으로 데이터를 저장한다.
→ 파일의 값에 실제 데이터를 저장한다(최대 크기 5TB)
→ 파일의 키는 각각의 객체를 고유하게 만들어주는 식별자 역할.
파일의 키를 이용하여 원하는 객체 검색 가능.
• 메타데이터
: 객체의 생성일, 크기, 유형과 같은 객체에 대한 정보가 담긴 데이터(객체를 설명하는 데이터).
6. 배포 전략(Deploy Strategy)

① AWS 서비스 중 하나인 S3를 이용하여 사용자에게 client application을 배포할 수 있다.
→ 로컬 환경에서는 자체 개발 서버 (예, create-react-app)를 이용해
클라이언트 앱을 실행시키는 것이 보통이기 때문에 EC2 인스턴스를 사용하는 것이 아닌
클라이언트 앱을 정적 파일로 빌드하여 제공한다.
✷ 빌드
: 불필요한 데이터를 없애고 여러 갈래로 퍼져있는 데이터들을 통합 / 압축하여 배포하기 최적화된 상태를 만드는 것.
⇒ 데이터의 용량이 줄어들고 웹 사이트의 로딩 속도가 빨라진다.
하지만 일반적인 의미의 빌드는, 소스코드를 실행 가능한 번들로 변환하는 컴파일 과정을 의미한다.
웹 앱에서와같이 HTML, CSS, JS의 형태로 배포하는 경우는 조금 다르다.
웹 앱은 배포 가능한 정적 파일(static files)의 형태로 만들어 줘야 한다.
asset 자체가 정적인 경우, 있는 그대로 배포하면 된다.
React의 경우 npm run build와 같은 명령을 사용해서,
정적 파일 형태의 결과물을 만들어 낸 후 배포하면 된다.
(사용하고 있는 환경에 따라 빌드 과정은 다를 수 있다.)
② 사용자들이 더 빠르게 파일을 받을 수 있게 하기 위해
AWS에서 제공하는 CDN 서비스인 CloudFront를 통해
각지의 데이터 센터에 데이터를 분산시켜 저장해뒀다가 가까운 지역에서 데이터를 주는 방식으로
사용자에게 더 빠르게 서비스(콘텐츠)를 제공할 수 있다.

③ 클라이언트 앱을 통해 요청을 전달할 서버 앱(Server Application)을 배포하는 방법은
AWS EC2 서비스(가상의 PC)를 통해 손쉽게 서버를 구성하고(서버 코드를 구동하고) 안정적인 서비스를 제공할 수 있다.
④ AWS에서 데이터베이스 특화 서비스인 RDS 서비스를 제공하여
AWS가 유지보수를 담당하는 RDS를 이용하여 즉시 데이터베이스를 사용할 수 있다.
⑤ RDS 서비스를 이용하여 EC2를 통해 배포된 서버 앱의 데이터를 저장, 제공하는 데이터베이스를 배포할 수 있다.

⑤ S3, EC2를 이용해서 배포된 서비스는 IP 주소 혹은 AWS에서 제공하는 서비스와는 전혀 상관없는
긴 도메인 주소를 통해 접근하게 되기 때문에 AWS에서 제공하는 Route53 서비스를 이용하여
직관적인 도메인 주소를 통해 서비스에 접근할 수 있게 한다.
'기술개념정리(in Javascript)' 카테고리의 다른 글
| 220328 D+68 도메인 주소를 이용한 HTTPS 인증 (0) | 2022.03.28 |
|---|---|
| 220325(28) D+67(68) 백엔드&프론트엔드 배포, 데이터베이스 연결 (0) | 2022.03.28 |
| 220324 D+66 Git Branch, 프로젝트 workflow (0) | 2022.03.25 |
| 220323 D+65 인터넷 프로토콜, HTTP 헤더, 웹 캐시 (0) | 2022.03.24 |
| 220321(22) D+63(64) 컴퓨터 공학 기초, 운영체제, 가비지 컬렉션, 캐시 (0) | 2022.03.22 |



