개발하고 싶은 초심자
220831 D+7 컬렉션(Collection) - 제네릭(Generic), 컬렉션 프레임워크(collection framework) 본문
220831 D+7 컬렉션(Collection) - 제네릭(Generic), 컬렉션 프레임워크(collection framework)
정새얀 2022. 8. 31. 21:591. 제네릭(Generic)
: 클래스나 메서드의 코드를 작성할 때 타입을 구체적으로 지정하는 것이 아닌 추후 지정할 수 있도록 일반화하는 것.
→ 작성한 클래스 또는 메서드의 코드가 특정 데이터 타입에 얽매이지 않게 해 둔 것.
// Box 클래스는 오로지 String 타입의 데이터만을 저장할 수 있는 인스턴스를 만들 수 있다.
// 다양한 타입의 데이터를 저장할 수 있는 객체를 만들고자 한다면 각 타입별로 별도의 클래스를 만들어야 한다.
class Box {
private String item;
Box(String item) {
this.item = item;
}
public String getItem() {
return item;
}
public void setItem(String item) {
this.item = item;
}
}
// <T>, T와 같은 제네릭을 사용하면 단 하나의 Box 클래스만으로 모든 타입의 데이터를 저장할 수 있는 인스턴스를 만들 수 있다.
class Box<T> {
private T item;
public Box(T item) {
this.item = item;
}
public T getItem() {
return item;
}
public void setItem(T item) {
this.item = item;
}
}
// Box 클래스를 인스턴스화 한 코드
// Box 클래스 내의 T를 String으로 바꿔라
Box<String> basket1 = new Box<String>("기타줄");
// 위의 코드를 실행해서 Box 클래스 내부의 T가 모두 String으로 치환되는 것처럼 동작하게 된다.
class Box {
private String item;
Box(String item) {
this.item = item;
}
public String getItem() {
return item;
}
public void setItem(String item) {
this.item = item;
}
}
// <>안에 Integer를 넣어 인스턴스화 하는 코드
// 클래스 내부의 T가 모두 Integer로 치환된다.
// Integer는 int의 래퍼 클래스(wrapper class)
Box<Integer> basket2 = new Basket<Integer>(1);
// 위와 같이 인스턴스화하면 Basket 클래스는 아래와 같이 변환된다.
class Box<Integer> {
private Integer item;
public Box(Integer item) {
this.item = item;
}
public Integer getItem() {
return item;
}
public void setItem(Integer item) {
this.item = item;
}
}✅ 래퍼 클래스
① 제네릭 클래스
: 제네릭이 사용된 클래스.
class Box<T> { // <>안에 넣어 클래스 이름 옆에 작성해줌으로써 클래스 내부에서 사용할 타입 매개변수를 선언할 수 있음.
private T item; // T: 타입 매개변수
public Box(T item) {
this.item = item;
}
public T getItem() {
return item;
}
public void setItem(T item) {
this.item = item;
}
}
// 타입 매개변수를 여러 개 사용해야 할 때 선언하는 방식
class Box<K, V> { ... }
타입 매개변수는 임의의 문자로 지정할 수 있습니다.
위에서 사용한 T, K, V는 각각 Type, Key, Value의 첫 글자를 따온 것.
이 외에 Element를 뜻하는 E, Number를 뜻하는 N, 그리고 Result를 뜻하는 R도 자주 사용된다.② 제네릭 클래스를 정의할 때 주의할 점
// 클래스 변수에는 타입 매개변수를 사용할 수 없음
class Box<T> {
private T item1; // O
static T item2; // X
}→ 클래스 변수에 타입 매개변수를 사용할 수 있다면,
Basket<String>으로 만든 인스턴스와, Basket<Integer>로 만든 인스턴스가 공유하는
클래스 변수의 타입이 서로 달라지게 되어, 클래스 변수를 통해 같은 변수를 공유하는 것이 아니게 된다.
⇒ static이 붙은 변수 또는 메서드에는 타입 매개변수를 사용할 수 없다.
③ 제네릭 클래스 사용
// 타입 매개변수에 치환될 타입으로 기본 타입을 지정할 수 없다
// int, double같은 원시 타입을 지정해야하는 맥락에서 Integer, Double같은 래퍼 클래스를 활용한다.
Box<String> Box1 = new Box<String>("Hello");
Box<Integer> Box2 = new Box<Integer>(10);
Box<Double> Box3 = new Box<Double>(3.14);
// 구체적인 타입은 생략하고 작성해도 됨 → 참조변수의 타입으로부터 유추할 수 있기 때문
Box<String> Box1 = new Box<>("Hello");
Box<Integer> Box2 = new Box<>(10);
Box<Double> Box3 = new Box<>(3.14);// 제네릭 클래스를 사용할 때 다형성을 적용할 수 있다.
// 타입을 지정하는 데에 제한이 없다.
class Flower { ... }
class Rose extends Flower { ... }
class RosePasta { ... }
// 제네릭 클래스 정의
class Basket<T> {
private T item;
public T getItem() {
return item;
}
public void setItem(T item) {
this.item = item;
}
}
public static void main(String[] args) {
Basket<Flower> flowerBasket = new Basket<>();
flowerBasket.setItem(new Rose()); // 다형성 적용
flowerBasket.setItem(new RosePasta()); // 에러
}⇒ new Rose()를 통해 생성된 인스턴스는 Rose 타입이며,
Rose 클래스는 Flower 클래스를 상속받고 있으므로, Basket<Flower>의 item에 할당될 수 있다.
Basket<Flower>은 결국 item의 타입을 Flower로 지정하는 것이고,
Flower 클래스는 Rose 클래스의 상위 클래스이기 때문이다.
⇒ new RosePasta()를 통해 생성된 인스턴스는 RosePasta 타입이며,
RosePasta 클래스는 Flower 클래스와 아무런 관계가 없어서 flowerBasket의 item에 할당될 수 없다.
④ 제한된 제네릭 클래스
// Basket 클래스를 인스턴스화할 때 타입으로 Flower 클래스의 하위 클래스만 지정하도록 제한된다
class Flower { ... }
class Rose extends Flower { ... }
class RosePasta { ... }
class Basket<T extends Flower> {
private T item;
...
}
public static void main(String[] args) {
// 인스턴스화
Basket<Rose> roseBasket = new Basket<>();
Basket<RosePasta> rosePastaBasket = new Basket<>(); // 에러
}
// 특정 인터페이스를 구현한 클래스만 타입으로 지정하도록 제한한다
// extends 키워드 사용
interface Plant { ... }
class Flower implements Plant { ... }
class Rose extends Flower implements Plant { ... }
class Basket<T extends Plant> {
private T item;
...
}
public static void main(String[] args) {
// 인스턴스화
Basket<Flower> flowerBasket = new Basket<>();
Basket<Rose> roseBasket = new Basket<>();
}
// 특정 클래스를 상속받으면서 동시에 특정 인터페이스를 구현한 타입으로 지정할 수 있도록 제한한다
interface Plant { ... }
class Flower implements Plant { ... }
class Rose extends Flower implements Plant { ... }
class Basket<T extends Plant & Flower> { // &를 사용하여 코드 작성
private T item;
...
}
public static void main(String[] args) {
// 인스턴스화
Basket<Flower> flowerBasket = new Basket<>();
Basket<Rose> roseBasket = new Basket<>();
}⑤ 제네릭 메서드
: 클래스 내부의 특정 메서드만 제네릭으로 선언할 수 있는 것.
→ 제네릭 메서드의 타입 매개변수 선언은 반환 타입 앞에서 이루어진다.
→ 해당 메서드 내에서만 선언한 타입 매개변수를 사용할 수 있다.
// 제네릭 메서드의 타입 매개변수는 제네릭 클래스의 타입 매개변수와 별개의 것이다.
// 동일하게 T라는 타입 매개변수명을 사용한다 하더라도 같은 알파벳 문자를 이름으로 사용하는 것일 뿐, 서로 다른 타입 매개변수다.
class Basket<T> { // ①번에서 선언한 타입 매개변수 T와
...
public <T> void add(T element) { // ②번에서 선언한 타입 매개변수 T는 서로 다르다
...
}
}→ 클래스명 옆에서 선언한 타입 매개변수는 클래스가 인스턴스화 될 때 타입이 지정된다
(타입이 지정되는 시점이 다르다는 것)
→ 제네릭 메서드에서 선언한 타입 매개변수의 구체적인 타입 지정은 메서드가 호출될 때 이루어진다.
Basket<String> basket = new Bakset<>(); // 위 예제의 ①의 T가 String으로 지정.
basket.<Integer>add(10); // 위 예제의 ②의 T가 Integer로 지정.
basket.add(10); // 타입 지정을 생략할 수도 있다.// 클래스 타입 매개변수와 다르게 메서드 타입변수는 static 메서드에서도 선언하여 사용할 수 있다
class Basket {
...
static <T> int setPrice(T element) {
...
}
}// 제네릭 메서드를 정의하는 시점에서 실제 어떤 타입이 입력 되는지 알 수 없다
// length()메서드처럼 String 클래스의 메서드는 제네릭 메서드를 정의하는 시점에서 사용 불가
class Basket {
public <T> void print(T item) {
System.out.println(item.length()); // 불가
}
}// 모든 클래스는 Object 클래스를 상속받기 때문에 Object 모든 자바의 최상위 클래스인 Object 클래스에서는 사용 가능
class Basket {
public <T> void getPrint(T item) {
System.out.println(item.equals("Harvey")); // 가능
}
}
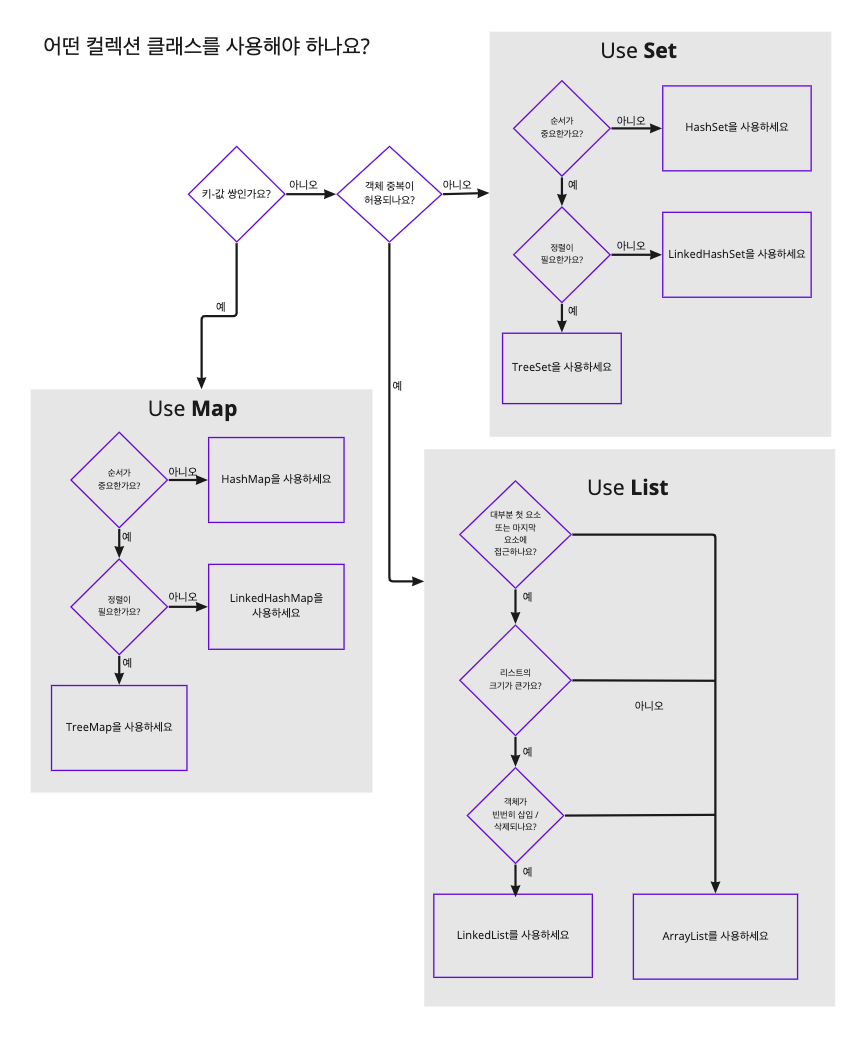
2. 컬렉션 프레임워크(Collection Framework)
: 데이터를 저장하기 위해 널리 알려져 있는 자료 구조를 바탕으로 객체들을 효율적으로 추가, 삭제, 검색할 수 있도록
컬렉션을 만들고, 관련된 인터페이스와 클래스를 포함시켜 둔 것을 총칭하는 것.
→ 특정 자료 구조에 데이터를 추가하고, 삭제하고, 수정하고, 검색하는 등의 동작을 수행하는 편리한 메서드들을 제공
✷ 컬렉션
: 여러 데이터들의 집합.

① 컬렉션 프레임워크의 주요 인터페이스
‣ List
: 배열과 같이 객체를 일렬로 늘어놓은 구조를 가지고 있음.
→ 객체를 인덱스로 관리하기 때문에 객체를 저장하면 자동으로 인덱스가 부여되고,
인덱스로 객체를 검색, 추가, 삭제할 수 있는 등의 여러 기능을 제공한다.
→ 데이터의 순서가 유지되며, 중복 저장이 가능한 컬렉션을 구현하는 데에 사용된다.
→ ArrayList, Vector, Stack, LinkedList 등이 List 인터페이스를 구현한다.
| 기능 | 리턴 타입 | 메서드 | 설명 |
| 객체 추가 | void | add(int index, Object element) | 주어진 인덱스에 객체를 추가 |
| boolean | addAll(int index, Collection c) | 주어진 인덱스에 컬렉션을 추가 | |
| Object | set(int index, Object element) | 주어진 위치에 객체를 저장 | |
| 객체 검색 | Object | get(int index) | 주어진 인덱스에 저장된 객체를 반환 |
| int | indexOf(Object o) / lastIndexOf(Object o) | 순방향 / 역방향으로 탐색하여 주어진 객체의 위치를 반환 | |
| ListIterator | listIterator() / listIterator(int index) |
List의 객체를 탐색할 수 있는ListIterator 반환 / 주어진 index부터 탐색할 수 있는 ListIterator 반환 |
|
| List | subList (int fromIndex, int toIndex) |
fromIndex부터 toIndex에 있는 객체를 반환 | |
| 객체 삭제 | Object | remove(int index) | 주어진 인덱스에 저장된 객체를 삭제하고 삭제된 객체를 반환 |
| boolean | remove(Object o) | 주어진 객체를 삭제 | |
| 객체 정렬 | void | sort(Comparator c) | 주어진 비교자(comparator)로 List를 정렬 |
‣ ArrayList
: List 인터페이스를 구현한 클래스로 기능적으로 Vector와 동일하지만 기존의 Vector를 개선한 것이다
→ 객체를 추가하면 객체가 인덱스로 관리된다는 점에서 배열과 비슷하지만
배열은 생성될 때 크기가 고정되고 크기를 변경할 수 없지만
ArrayList는 저장 용량을 초과하여 객체들이 추가되면 자동으로 저장 용량이 늘어나고 데이터의 순서를 유지한다.
(리스트 계열 자료구조의 특성을 이어받아 데이터가 연속적으로 존재한다)
List<타입 매개변수> 객체명 = new ArrayList<타입 매개변수>(초기 저장 용량);
List<String> container1 = new ArrayList<String>();
// String 타입의 객체를 저장하는 ArrayList 생성
// 초기 용량이 인자로 전달되지 않으면 기본적으로 10으로 지정된다.
List<String> container2 = new ArrayList<String>(30);
// String 타입의 객체를 저장하는 ArrayList 생성
// 초기 용량을 30으로 지정했다.
→ ArrayList에 객체를 추가하면 인덱스 0부터 차례대로 저장된다.
특정 인덱스의 객체를 제거하면 바로 뒤 인덱스부터 마지막 인덱스까지 모두 1씩 앞으로 당겨진다.
(빈번한 객체 삽입과 삭제가 일어나는 곳에서는 LinkedList를 사용하는 것이 좋다)// ArrayList에 String 객체를 추가, 검색, 삭제하는 예제
public class ArrayListExample {
public static void main(String[] args) {
// ArrayList를 생성하여 list에 할당
List<String> list = new ArrayList<String>();
// String 타입의 데이터를 ArrayList에 추가
list.add("Java");
list.add("egg");
list.add("tree");
// 저장된 총 객체 수 얻기
int size = list.size();
// 0번 인덱스의 객체 얻기
String skill = list.get(0);
// 저장된 총 객체 수 만큼 조회
for(int i = 0; i < list.size(); i++){
String str = list.get(i);
System.out.println(i + ":" + str);
}
// for-each문으로 순회
for (String str: list) {
System.out.println(str);
}
// 0번 인덱스 객체 삭제
list.remove(0)
}
}
→ ArrayList에서 데이터 추가 / 삭제하기 위해 데이터를 복사해서 이동해야한다.
객체를 순차적으로 저장할 때 데이터를 이동하지 않아도 되기 때문에 작업 속도가 빠르지만,
중간에 위치한 객체를 추가 / 삭제할 때 데이터 이동이 많이 일어나 속도가 저하된다.
⇒ 데이터를 순차적으로 추가 / 삭제(0번 인덱스부터 데이터를 추가 / 마지막 인덱스부터 데이터를 삭제)할 때,
인덱스를 통해 바로 데이터에 접근할 수 있기 때문에 데이터를 읽어들이는 경우(검색 / 읽기)에 유리하다.
→ 중간에 데이터를 추가하거나, 중간에 위치하는 데이터를 삭제하는 경우에는
해당 데이터의 뒤에 위치한 값들을 뒤로 밀어주거나 앞으로 당겨주어야 하기 때문에 비효율적이다.
⇒ 데이터의 개수가 변하지 않는 상황에서 ArrayList를 사용하는 것이 좋다.
‣ LinkedList
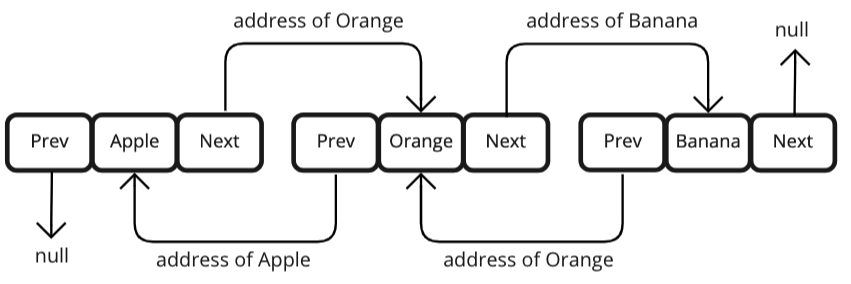
→ 각 요소(node)들은 자신과 연결된 이전 요소 및 다음 요소의 주소값과 데이터로 구성되어있다.
→ 중간에 데이터를 추가하면 저장되어있는 주소값만 변경해주기 때문에 각 요소들을 뒤로 밀어내지 않아도 된다.
→ 데이터를 삭제하려면 삭제하고자 하는 요소의 이전 요소가 삭제하고자 하는 요소의 다음 요소를 참조하도록 변경한다.
(링크를 끊어주는 방식)
⇒ 배열처럼 데이터를 이동하기 위해 복사할 필요가 없기 때문에 ArrayList보다 처리 속도가 훨씬 빠르다.
데이터 검색 시 시작 인덱스부터 찾고자 하는 데이터까지 순차적으로 각 요소들에 접근해야 하기 때문에 속도가 느리다.
→ 데이터를 추가할 때도 새로운 요소를 추가하고자 하는 위치의 이전 요소와 다음 요소 사이에 연결해준다.
⇒ 이전 요소가 새로운 요소를 참조하고, 새로운 요소가 다음 요소를 참조하게 만드는 것이다.
public class LinkedListExample {
public static void main(String[] args) {
// Linked List를 생성하여 list에 할당
List<String> list = new LinkedList<>();
// String 타입의 데이터를 LinkedList에 추가
list.add("Java");
list.add("egg");
list.add("tree");
// 저장된 총 객체 수 얻기
int size = list.size();
// 0번 인덱스의 객체 얻기
String skill = list.get(0);
// 저장된 총 객체 수 만큼 조회
for(int i = 0; i < list.size(); i++){
String str = list.get(i);
System.out.println(i + ":" + str);
}
// for-each문으로 순회
for (String str: list) {
System.out.println(str);
}
// 0번 인덱스 객체 삭제
list.remove(0);
}
}⇒ 데이터의 잦은 변경이 예상될 때는 LinkedList를 사용하는 것이 좋다.
‣ Iterator
: 컬렉션에 저장된 요소들을 순차적으로 읽어오는 역할.
→ Iterator의 컬렉션 순회 기능은 Iterator 인터페이스에 정의되어져 있으며,
Collection 인터페이스에 Iterator 인터페이스를 구현한 클래스의 인스턴스를 반환하는 메서드 iterator()가 정의되어있다.
⇒ Collection 인터페이스에 정의된 iterator()를 호출하면 iterator 타입의 인스턴스가 반환된다.
Collection 인터페이스를 상속받는 List와 Set 인터페이스를 구현한 클래스들은 iterator()메서드를 사용할 수 있다.
| 메서드 | 설명 |
| hasNext() | 읽어올 객체가 남아 있으면 true를 리턴하고, 없으면 false를 리턴한다. |
| next() | 컬렉션에서 하나의 객체를 읽어온다. 이 때, next()를 호출하기 전에 hasNext()를 통해 읽어올 다음 요소가 있는지 먼저 확인해야 한다. |
| remove() | next()를 통해 읽어온 객체를 삭제한다. next()를 호출한 다음에 remove()를 호출해야 한다. |
→ Iterator를 활용하여 컬렉션의 객체를 읽어올 때에는 next() 메서드를 사용한다.
next() 메서드를 사용하기 전에는 먼저 가져올 객체가 있는지 hasNext()를 통해 확인하는 것이 좋다.
→ hasNext() 메서드는 읽어올 다음 객체가 있으면, true를 리턴하고, 더 이상 가져올 객체가 없으면 false를 리턴한다.
⇒ true가 리턴될 때에만 next()메서드가 동작하도록 코드를 작성해야 한다.
List<String> list = ...;
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) { // 읽어올 다음 객체가 있다면
String str = iterator.next(); // next()를 통해 다음 객체를 읽어온다.
...
}
// iterator를 사용하지 않아도 for-each문을 이용해 전체 객체를 대상으로 반복 가능
List<String> list = ...;
for(String str : list) {
...
}next() 메서드로 가져온 객체를 컬렉션에서 제거하고 싶다면 remove() 메서드를 호출하면 된다.
→ next() 메서드는 컬렉션의 객체를 그저 읽어오는 메서드로, 실제 컬렉션에서 객체를 빼내는 것은 아니지만
remove() 메서드는 컬렉션에서 실제로 객체를 삭제한다.
List<String> list = ...;
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){ // 다음 객체가 있다면
String str = iterator.next(); // 객체를 읽어오고,
if(str.equals("str과 같은 단어")){ // 조건에 부합한다면
iterator.remove(); // 해당 객체를 컬렉션에서 제거한다.
}
}
‣ Set
: 요소의 중복을 허용하지 않고, 저장 순서를 유지하지 않는 컬렉션.
→ 데이터의 순서가 유지되지 않으며, 중복 저장이 불가능한 컬렉션을 구현하는 데에 사용된다.
HashSet, TreeSet 등이 Set 인터페이스를 구현한다.
| 기능 | 리턴 타입 | 메서드 | 설명 |
| 객체 추가 | boolean | add(Object o) | 주어진 객체를 추가하고, 성공하면 true를, 중복 객체면 false를 반환합니다. |
| 객체 검색 | boolean | contains(Object o) | 주어진 객체가 Set에 존재하는지 확인합니다. |
| boolean | isEmpty() | Set이 비어있는지 확인합니다. | |
| Iterator | Iterator() | 저장된 객체를 하나씩 읽어오는 반복자를 리턴합니다. | |
| int | size() | 저장되어 있는 전체 객체의 수를 리턴합니다. | |
| 객체 삭제 | void | clear() | Set에 저장되어져 있는 모든 객체를 삭제합니다. |
| boolean | remove(Object o) | 주어진 객체를 삭제합니다. |
‣ HashSet
: Set 인터페이스 특성을 그대로 물려받아 중복된 값을 허용하지 않고 저장 순서를 유지하지 않는다.
→ HashSet에 값을 추가할 때 해당 값이 중복된 값인지 판단하는 과정
① add(Object o)를 통해 객체를 저장하고자 한다.
② 이 때, 저장하고자 하는 객체의 해시코드를 hashCode() 메서드를 통해 얻어낸다.
③ Set이 저장하고 있는 모든 객체들의 해시코드를 hashCode() 메서드로 얻어낸다.
④ 저장하고자 하는 객체의 해시코드와,
Set에 이미 저장되어져 있던 객체들의 해시코드를 비교하여 같은 해시코드가 있는지 검사한다.
‣ 같은 해시코드를 가진 객체가 존재한다면 저장하고자 했던 객체가 중복 객체로 간주되어 Set에 추가되지 않으며,
add(Object o) 메서드가 false를 리턴한다.
‣ 같은 해시코드를 가진 객체가 존재하지 않으면 Set에 객체가 추가되며 add(Object o) 메서드가 true를 리턴한다.
⑤ equals() 메서드를 통해 객체를 비교한다.
‣ true가 리턴된다면 중복 객체로 간주되어 Set에 추가되지 않으며, add(Object o)가 false를 리턴한다.
‣ false가 리턴된다면 Set에 객체가 추가되며, add(Object o) 메서드가 true를 리턴한다.import java.util.*;
public class Main {
public static void main(String[] args) {
// HashSet 생성
HashSet<String > languages = new HashSet<String>();
// HashSet에 객체 추가
languages.add("Java");
languages.add("Python");
languages.add("Javascript");
languages.add("C++");
languages.add("Kotlin");
languages.add("Ruby");
languages.add("Java"); // 중복
// 반복자 생성하여 it에 할당
Iterator it = languages.iterator();
// 반복자를 통해 HashSet을 순회하며 각 요소들을 출력
while(it.hasNext()) {
System.out.println(it.next());
}
}
}‣ TreeSet
: 이진 탐색 트리 형태로 데이터를 저장한다.
→ 기본 정렬 방식은 오름차순이다.
→ 데이터의 중복 저장을 허용하지 않고 저장 순서를 유지하지 않는 Set 인터페이스의 특징은 그대로 유지됨.
✷ 이진 탐색 트리(Binary Search Tree)
: 하나의 부모 노드가 최대 두 개의 자식 노드와 연결되는 이진 트리의 일종, 정렬과 검색에 특화된 자료 구조.
→ 모든 왼쪽 자식의 값이 루트나 부모보다 작고, 모든 오른쪽 자식의 값이 루트나 부모보다 큰 값을 가진다.
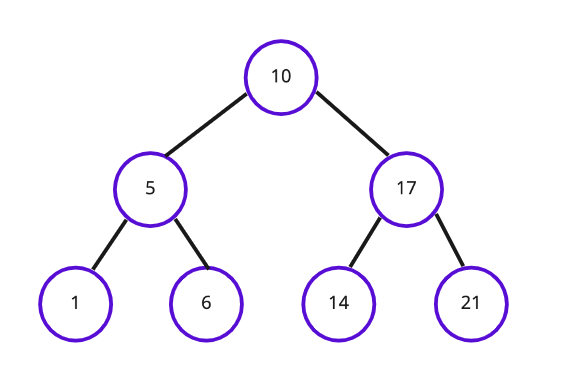
class Node {
Object element; // 객체의 주소값을 저장하는 참조변수
Node left; // 왼쪽 자식 노드의 주소값을 저장하는 참조변수
Node right; // 오른쪽 자식 노드의 주소값을 저장하는 참조변수
}import java.util.TreeSet;
public class TreeSetExample {
public static void main(String[] args) {
// TreeSet 생성
TreeSet<String> workers = new TreeSet<>();
// TreeSet에 요소 추가
workers.add("Lee Java");
workers.add("Park Hacker");
workers.add("Kim Coding");
System.out.println(workers);
System.out.println(workers.first());
System.out.println(workers.last());
System.out.println(workers.higher("Lee"));
System.out.println(workers.subSet("Kim", "Park"));
}
}
→ 요소를 추가하기만 했지만 자동으로 사전 편찬 순에 따라 오름차순으로 정렬되었다.
→ List와 Set은 서로 공통점이 많아 위 그림과 같이 Collection이라는 인터페이스로 묶인다.
⇒ 이 둘의 공통점이 추출되어 추상화된 것이 바로 Collection이라는 인터페이스.
‣ Map
: 키(key)와 값(value)으로 구성된 객체(Entry 객체)를 저장하는 구조를 가지고 있다.
→ Entry 객체는 키와 값을 각각 Key 객체, Value 객체로 저장한다.
키(key)와 값(value)의 쌍으로 데이터를 저장하는 컬렉션을 구현하는 데에 사용됩니다.
데이터의 순서가 유지되지 않으며, 키는 값을 식별하기 위해 사용되므로 중복 저장이 불가능하지만, 값은 중복 저장 가능.
→ HashMap, HashTable, TreeMap, Properties 등
⇒ List가 인덱스를 기준으로 관리되는 반면,
Map은 키(key)로 객체들을 관리하기 때문에 키를 매개값으로 갖는 메서드가 많다
| 기능 | 리턴 타입 | 메서드 | 설명 |
| 객체 추가 | Object | put(Object key, Object value) | 주어진 키로 값을 저장한다. 해당 키가 새로운 키일 경우 null을 리턴하지만, 동일한 키가 있을 경우에는 기존의 값을 대체하고 대체되기 이전의 값을 리턴한다. |
| 객체 검색 | boolean | containsKey(Object key) | 주어진 키가 있으면 true, 없으면 false를 리턴한다. |
| boolean | containsValue(Object value) | 주어진 값이 있으면 true, 없으면 false를 리턴한다. | |
| Set | entrySet() | 키와 값의 쌍으로 구성된 모든 Map.Entry 객체를 Set에 담아서 리턴한다. |
|
| Object | get(Object key) | 주어진 키에 해당하는 값을 리턴한다. | |
| boolean | isEmpty() | 컬렉션이 비어 있는지 확인한다. | |
| Set | keySet() | 모든 키를 Set 객체에 담아서 리턴한다. | |
| int | size() | 저장된 Entry 객체의 총 갯수를 리턴한다. | |
| Collection | values() | 저장된 모든 값을 Collection에 담아서 리턴한다. | |
| 객체 삭제 | void | clear() | 모든 Map.Entry(키와 값)을 삭제한다. |
| Object | remove(Object key) | 주어진 키와 일치하는 Map.Entry를 삭제하고 값을 리턴한다. |
‣ HashMap
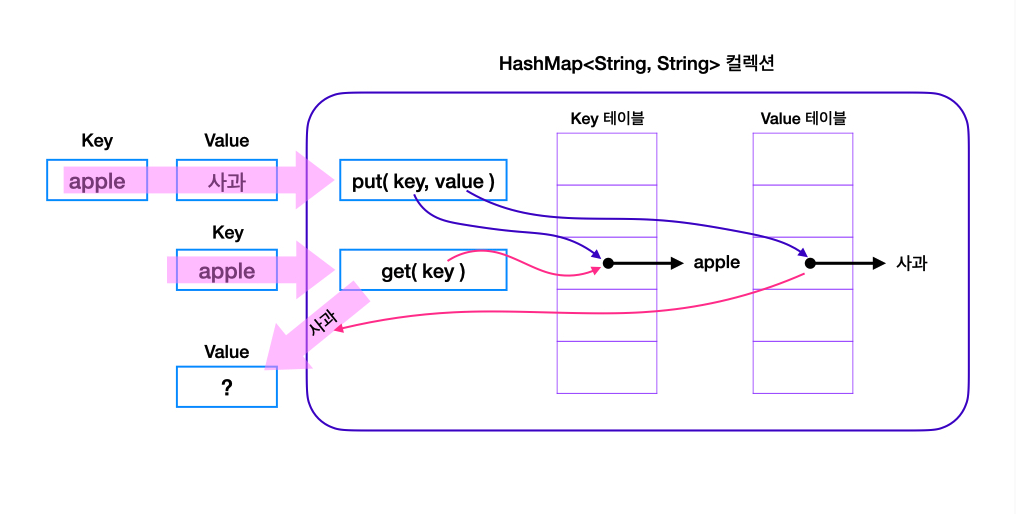
→ 키와 값으로 구성된 Entry 객체를 저장한다.
→ 해시 함수를 통해 '키'와 '값'이 저장되는 위치를 결정하기 때문에
사용자는 그 위치를 알 수 없고, 삽입되는 순서와 위치 또한 관계가 없다.
⇒ 이름 그대로 해싱(Hashing)을 사용하기 때문에 많은 양의 데이터를 검색하는 데 있어서 뛰어난 성능을 보인다.
// HashMap을 생성할 때 키와 값의 타입을 따로 지정해줘야 한다.
HashMap<String, Integer> hashmap = new HashMap<>();
import java.util.*;
public class HashMapExample {
public static void main(String[] args) {
// HashMap 생성
HashMap<String, Integer> map = new HashMap<>();
// Entry 객체 저장
map.put("피카츄", 85);
map.put("꼬부기", 95);
map.put("야도란", 75);
map.put("파이리", 65);
map.put("피존투", 15);
// 저장된 총 Entry 수 얻기
System.out.println("총 entry 수: " + map.size());
// 객체 찾기
System.out.println("파이리 : " + map.get("파이리"));
// key를 요소로 가지는 Set을 생성 -> 아래에서 순회하기 위해 필요합니다.
Set<String> keySet = map.keySet();
// keySet을 순회하면서 value를 읽어옵니다.
Iterator<String> keyIterator = keySet.iterator();
while(keyIterator.hasNext()) {
String key = keyIterator.next();
Integer value = map.get(key);
System.out.println(key + " : " + value);
}
// 객체 삭제
map.remove("피존투");
System.out.println("총 entry 수: " + map.size());
// Entry 객체를 요소로 가지는 Set을 생성 -> 아래에서 순회하기 위해 필요합니다.
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
// entrySet을 순회하면서 value를 읽어옵니다.
Iterator<Map.Entry<String, Integer>> entryIterator = entrySet.iterator();
while(entryIterator.hasNext()) {
Map.Entry<String, Integer> entry = entryIterator.next();
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key + " : " + value);
}
// 객체 전체 삭제
map.clear();
}
}→ Map은 키와 값을 쌍으로 저장하기 때문에 iterator()를 직접 호출할 수 없지만
keySet()이나 entrySey() 메서드를 이용하여 Set 형태로 반환된 컬렉션에
iterator()를 호출하여 반복자를 만들고 반복자를 통해 순회할 수 있다.
‣ HashTable
// 로그인 기능 구현
import java.util.*;
public class HashTableExample {
public static void main(String[] args){
HashTable<String, String> map = new Hashtable<String, String>();
map.put("Spring", "345");
map.put("Summer", "678");
map.put("Fall", "91011");
map.put("Winter", "1212");
System.out.println(map);
Scanner scanner = new Scanner(System.in);
while (true) {
System.out.println("아이디와 비밀번호를 입력해 주세요");
System.out.println("아이디");
String id = scanner.nextLine();
System.out.println("비밀번호");
String password = scanner.nextLine();
if (map.containsKey(id)) {
if (map.get(id).equals(password)) {
System.out.println("로그인 되었습니다.");
break;
} else System.out.println("비밀번호가 일치하지 않습니다. ");
} else System.out.println("입력하신 아이디가 존재하지 않습니다.");
}
}
}
② Collection 인터페이스의 메서드들
| 기능 | 리턴 타입 | 메서드 | 설명 |
| 객체 추가 | boolean | add(Object o) / addAll(Collection c) |
주어진 객체 및 컬렉션의 객체들을 컬렉션에 추가한다. |
| 객체 검색 | boolean | contains(Object o) / containsAll(Collection c) | 주어진 객체 및 컬렉션이 저장되어 있는지 여부를 리턴한다. |
| Iterator | iterator() | 컬렉션의 iterator를 리턴한다. | |
| boolean | equals(Object o) | 컬렉션이 동일한지 여부를 확인한다. | |
| boolean | isEmpty() | 컬렉션이 비어있는지 여부를 확인한다. | |
| int | size() | 저장되어 있는 전체 객체 수를 리턴한다. | |
| 객체 삭제 | void | clear() | 컬렉션에 저장된 모든 객체를 삭제한다. |
| boolean | remove(Object o) / removeAll(Collection c) | 주어진 객체 및 컬렉션을 삭제하고 성공 여부를 리턴한다. | |
| boolean | retainAll(Collection c) | 주어진 컬렉션을 제외한 모든 객체를 컬렉션에서 삭제하고, 컬렉션에 변화가 있는지의 여부를 리턴한다. |
|
| 객체 변환 | Object[] | toArray() | 컬렉션에 저장된 객체를 객체배열(Object [])로 반환한다. |
| Object[] | toArray(Object[] a) | 주어진 배열에 컬렉션의 객체를 저장해서 반환한다. |