
개발하고 싶은 초심자
220315 D+59 MongoDB(Basic, CRUD), Aggregation Framework 본문
220315 D+59 MongoDB(Basic, CRUD), Aggregation Framework
정새얀 2022. 3. 15. 17:521. NoSQL 기반의 비관계형 데이터베이스
‣ 비구조적인 대용량의 데이터를 저장하는 경우
→ 비관계형 데이터베이스이기 때문에 자유로운 형태로 데이터를 저장할 수 있음.
→ 필요에 따라 새로운 데이터 유형을 추가할 수 있음.
→ 소프트웨어 개발에 정형화되지 않은 많은 양의 데이터가 필요한 경우 효율적임.
‣ 클라우드 컴퓨팅 및 저장 공간을 최대한 활용하는 경우
→ 데이터베이스를 클라우드 기반으로 쉽게 분리할 수 있도록 지원한다.
→ 저장공간을 효율적으로 사용한다.
→ 수평적 확장의 형태로 데이터베이스를 증설하므로 이론상 무한대로 서버를 계속 분산시켜 증설할 수 있음.
‣ 빠르게 서비스를 구축하고 데이터 구조를 자주 업데이트하는 경우
→ 스키마를 미리 준비할 필요가 없기 때문에(스키마와 데이터 타입이 유연하다)
개발을 빠르게 해야 하는 때에 적합하다.
ex) 시장에 빠르게 프로토타입을 출시해야 하는 경우,
버전별로 많은 다운타임 없이 데이터 구조를 자주 업데이트해야 하는 경우.
✷ 다운타임: 데이터베이스의 서버를 오프라인으로 전환하여 작업하는 시간
2. MongoDB
: 대표적인 NoSQL 도큐먼트 데이터베이스.
‣ 도큐먼트 데이터베이스(Document Database)
: 데이터를 테이블이 아닌, 문서처럼 저장하는 데이터베이스.
→ 일반적으로 도큐먼트 데이터베이스에서는 JSON 유사 형식으로 데이터를 문서화한다.
→ 각각의 도큐먼트는 데이터를 필드-값의 형태로 가지고 있고, 컬렉션이라고 하는 그룹으로 묶어서 관리한다.
① 도큐먼트(document)
: 필드-값 쌍으로 저장된 데이터.
// JSON 형식으로 도큐먼트를 작성한 예시
{
<field>:<value>,
<field>:<value>,
"name":"Emily",
"age":29,
"address":"pelican city"
}
1. {}중괄호로 도큐먼트가 시작하고 끝난다.
2. 필드와 값이 :콜론으로 분리되어야하며,
필드와 값을 포함하는 쌍은 ,쉼표로 구분된다.
3. 문자열인 필드도 ""쌍따옴표로 감싼다.
⇒ 3가지 중 하나라도 충족되지 않으면 유효한 도큐먼트가 아님.
‣ 필드(field): 데이터의 고유한 식별자
‣ 값(value): 주어진 식별자와 관련된 데이터
‣ 컬렉션(collection): MongoDB의 도큐먼트로 구성된 저장소. 도큐먼트의 모음.
→ 데이터베이스는 여러 개의 컬렉션으로 구성된다.
⇒ 일반적으로 도큐먼트 간의 공통 필드가 있고,
데이터베이스 당 많은 컬렉션이 있으며 컬렉션 당 많은 도큐먼트가 있을 수 있다.
② JSON 형식으로 도큐먼트 작성하기
→ 텍스트 형식이기 때문에 읽기 쉽고 개발자들이 사용하기 편리한 형태를 가지고 있지만
파싱이 느리고 메모리 사용이 비효율적이라는 단점을 가지고 있음.
③ BSON(Binary JSON)형식

: 컴퓨터에 가까운 이진법에 기반을 둔 표현법.
→ JSON보다 메모리 사용이 효율적이고 빠르며 가볍고, 유연하다.
→ 더 많은 데이터 타입을 사용할 수 있다.
⇒ MongoDB는 JSON 형식으로 작성된 것은 무엇이든 데이터베이스에 추가할 수 있고, 쉽게 조회할 수 있다.
그러나 그 내부에서는 속도, 효율성, 유연성의 장점이 있는 BSON으로 데이터를 저장, 사용하고 있다.
3. Atlas Cloud
: GUI와 CLI로 데이터를 시각화, 분석, 내보내기, 빌드하는 데에 사용할 수 있음.
→ 아틀라스 사용자는 클러스터를 배포할 수 있으며, 클러스터는 그룹화된 서버에 데이터를 저장한다.

‣ 클러스터
: 데이터를 저장하는 서버 그룹.
→ 여러 대의 컴퓨터를 네트워크를 통해 연결하여 하나의 단일 컴퓨터처럼 동작하도록 제작한 컴퓨터.
‣ 레플리카 세트
: 동일한 데이터를 저장하는 몇 개의 연결된 MongoDB 인스턴스의 모음.
데이터의 사본을 저장하는 인스턴스의 모음.
→ 인스턴스 중 하나에 문제가 발생하더라도 데이터는 그대로 유지됨.
나머지 레플리카 세트의 인스턴스에 저장된 데이터로 작업이 가능함.
⇒ 도큐먼트나 컬렉션을 변경할 경우, 변경된 데이터의 중복 사본이 레플리카 세트에 저장된다.
이 설정 덕분에 레플리카 세트의 인스턴스 중 하나에 문제가 발생하더라도 데이터는 그대로 유지되며,
레플리카 세트의 애플리케이션에서 나머지 작업을 할 수 있다.
이 과정을 위해 클러스터(서버 그룹)를 배포하면, 자동으로 레플리카 세트가 구성된다.
‣ 인스턴스
: 특정 소프트웨어를 실행하는 로컬 / 클라우드의 단일 머신.
→ MongoDB에서는 데이터베이스를 의미함.
4. Importing(데이터 가져오기) & Exporting(데이터 내보내기)
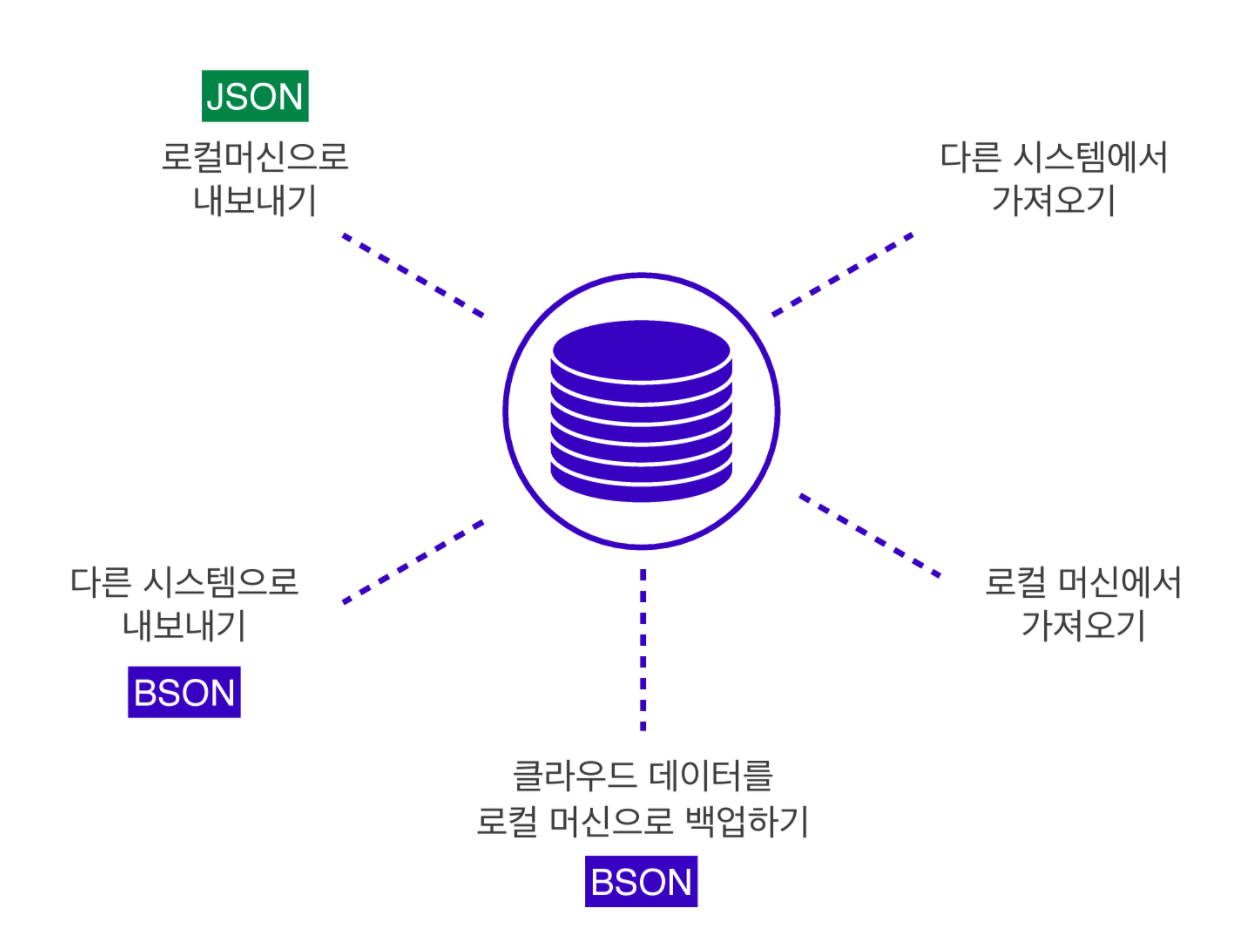
‣ MongoDB의 데이터는 가볍고 빠른 BSON의 형태로 저장되고,
데이터를 내보낸 후 조회 / 출력을 할 때는 읽기 쉬운 JSON의 형태로 출력된다.
→ 조건에 따라 가져오거나 내보낼 때 사용 가능한 명령어가 존재한다.
① Export 명령어
⇒ 이 명령어들을 사용하기 위해서 Atlas Cluster URI가 필요함.
: 일반 웹의 URI와 형식이 같고, username, password, cluster 주소로 이루어져 있음.

‣ mongodump(BSON)
: 별다른 쿼리가 없음.
‣ mongoexport(JSON)
: 내보낼 데이터베이스의 컬렉션 이름, 파일 이름까지 정확하게 작성해주어야 함.
② Import 명령어
: URI를 사용하여 작성한다.
drop쿼리문(기존에 있는 데이터를 삭제하기 위한 옵션)은 선택적 사용 가능.

‣ mongorestore(BSON)
‣ mongoimport(JSON)
5. MongoDB CRUD
‣ MongoDB 도큐먼트의 공통점 _id
{"_id" : "1a"} {"_id" : "2b"} {"_id" : "4c"}→ _id 필드의 값은 각 도큐먼트를 구별하는 역할을 하며,
모든 도큐먼트는 기본값으로 반드시 _id 필드를 가지고 있어야 한다.
→ _id 값이 다르면 내부의 필드와 값이 똑같아도 서로 다른 도큐먼트로 간주한다.
_id 값이 같으면 도큐먼트 내 필드와 값이 달라도 서로 같은 도큐먼트로 간주하여 에러를 발생시킨다.
⇒ 각 도큐먼트는 고유한 _id 값을 가지고 있어야 함.
→ 새로운 도큐먼트를 추가할 때 _id 값에 임의적으로 고유한 값을 생성해서 사용할 수도 있지만
보통은 ObjectId타입(12byte, 24chr)의 값으로 사용한다.
→ 도큐먼트를 추가할 때 자동으로 _id 필드가 생성되고 값에 ObjectId 값이 할당된다.
(_id 필드와 값을 특정한 경우는 제외)
‣ mongo shell을 이용한 컬렉션의 CRUD
① Insert(Create)
터미널을 사용해 아틀라스 클러스터에 연결한다.

Connect - Connect with the MongoDB Shell 클릭

운영체제(나는 macOS)에 맞게 다운로드 받은 후 2번에 나와있는 명령어를 터미널에 복사 + 붙여넣기.

터미널에 이런 식으로 뜸.
MongoDB에서 제공하는 샘플 데이터를 받아온다.

우측에 점 세 개 같은 걸 클릭해보면 Load Sample Dataset이라는 메뉴가 있다.
클릭하여 샘플 데이터 받아오기(어느 정도의 시간이 소요된다.)
다 받아와 지면 Connect 해서 위와 같은 과정을 반복함.
터미널에 show dbs; 명령어를 입력하면

샘플 데이터들이 받아와 진 것을 확인할 수 있다.
이러한 smaple_로 시작하는 데이터베이스가 MongoDB가 테스트용으로 제공하는 더미(dummy)이다.
show dbs
use 데이터베이스이름
show collections
① insert()를 사용하여 하나의 도큐먼트를 삽입하는 방법
insert()의 괄호 안에 삽입하고자 하는 도큐먼트를 작성한다.
db.컬렉션이름.insert()작성하고 나면 이 명령어에 따른 결과물이 하단에 WriteResult로 출력된다.

✷ nInserted 항목이 0으로 나오는 것을 보고 삽입된 도큐먼트의 수가 없다는 것을 알 수 있고,
이는 도큐먼트 추가에 실패했다는 것을 보여준다.
✷ duplicate key 에러
: 이미 같은 _id 값을 가지는 도큐먼트가 컬렉션 내부에 존재하기 때문에 중복된 데이터는 삽입할 수 없다는 의미.

위에서는 _id값을 넣고 결과를 봤지만, 이번에는 _id값을 삭제한 후 삽입 작업을 실행했다.
그 결과 WriteResult({“nInserted” : 1}) 로
zips 컬렉션에 우리가 작성한 1개의 도큐먼트가 삽입되었다는 것을 볼 수 있다.

find명령어로 데이터를 조회했다.
db.컬렉션이름.find()주황색 블록은 기존에 존재하던 도큐먼트, 파란색 블록은 추가한 도큐먼트다.
파란색 블록에는 _id 필드값을 추가하지 않았어도 도큐먼트가 삽입될 때 자동으로 해당값이 추가되었다.
또한 기본 값으로 ObjectId를 생성하여 할당했다는 것을 볼 수 있다.
⇒ _id값에 따라 도큐먼트가 구별된다.
② 다수의 도큐먼트를 삽입하는 방법
‣ _id값이 주어지지 않은 경우

inspections라는 컬렉션에 다수의 도큐먼트를 삽입하는 예시이다.
한 번에 다수의 도큐먼트를 삽입하려면 배열 안에 해당하는 도큐먼트를 담아주어야 한다.
→ test라는 1개의 필드를 가지고 있고 _id값은 주어지지 않았다.
⇒ 구조상 / 내용상 중복되지 않은 도큐먼트들.
⇒ "nInserted" 값이 3인 것을 보아 전부 추가되었음을 알 수 있다.
‣ _id값을 지정한 경우

첫 번째 도큐먼트와 두 번째 도큐먼트에는 동일한 _id 값을 주어 duplicate key 에러가 발생했다.
주황색 블록 안의 nInserted 항목에 1개의 도큐먼트, 인덱스가 2번인 마지막 도큐먼트가 삽입된 것을 알 수 있다.
하늘색 블록에는 첫 번째 도큐먼트인 {“test” : “1” }이 삽입된 것을 볼 수 있다.

하늘색 블록 안의 에러 메시지를 보면
0번 인덱스를 갖는 도큐먼트는 이미 이전에 삽입한 도큐먼트이기 때문에 duplicate key 에러가 났다.
1번 인덱스를 갖는 도큐먼트는 0번 인덱스의 도큐먼트와 _id값이 같기 때문에 duplicate key 에러가 난다.
⇒ 그래서 insert() 명령어를 통해 inspections 컬렉션에 추가된 도큐먼트는 인덱스가 2번인 마지막 도큐먼트이다.
✷ 존재하지 않는 컬렉션에 도큐먼트를 삽입한 경우에는 에러가 나지 않는다.
→ MongoDB는 사용자가 쉽게 새로운 컬렉션이나 데이터베이스를 생성하기를 원했기 때문에
만약 사용자가 존재하지 않는 컬렉션에 도큐먼트를 넣는 경우, 그와 동시에 컬렉션이 만들어지게 된다.
② find(Read)
‣ 하나의 조건으로 데이터 조회하기
기본명령어
db.컬렉션이름.find({쿼리문})
db.zips.find({"state":"NY"})를 통해 나온 결과이다.
많은 결과가 나와 전부 캡처할 수 없었지만, JSON 형식으로 출력되는 것을 확인할 수 있다.
→ 화면에 출력된 것은 랜덤 하게 선택된 20개의 결과물들이며 실제 결과물은 훨씬 더 많다.
→ 해당 조건에 맞는 다음 20개의 도큐먼트를 조회하려면 iterate의 줄임말인 it 명령어를 사용한다.
‣ 특정한 여러 개의 조건으로 데이터 조회하기
db.컬렉션이름.find({쿼리문1, 쿼리문2})
db.zips.find({“state” : “NY”, “city” : “ALBANY”}) 명령어로 나온 결과이다.
→ 총 7개의 데이터이기 때문에 it을 타이핑하라는 문구는 뜨지 않는다.
‣ 모든 데이터 조회하기
db.컬렉션이름.find()→ 조건 쿼리문을 따로 작성하지 않고 저대로만 작성하면 된다.
‣ 도큐먼트의 구조와 각각의 필드 - 값 쌍을 읽기 편하게 만들어주는 방법
db.컬렉션이름.find().pretty()
‣ 데이터의 수를 조회하는 명령어
db.컬렉션이름.find().count()
‣ 특정한 1개의 데이터를 조회하는 명령어
db.컬렉션이름.findOne({"_id":ObjectId("특정값")})
‣ 무작위의 데이터 1개만 조회하는 명령어
db.컬렉션이름.findOne()
③ Update
‣ updateOne
: 주어진 기준에 맞는 다수의 도큐먼트가 있을 때,
기준에 맞는 첫 번째 도큐먼트 하나만 업데이트가 된다.
‣ updateMany
: 쿼리문과 일치하는 모든 도큐먼트를 업데이트한다.
db.컬렉션이름.updateMany({업데이트 할 도큐먼트 결정하는 조건}, {$inc:{특정 필드: 특정한 필드의 값을 주어진 만큼 증가}})
→ MQL 연산자 $inc를 사용하여 업데이트하려는 필드와 증가하려는 값을 작성하여
다양한 필드의 값을 동시에 업데이트할 수 있다.
{$inc:
{"필드1":increment value1,
{"필드2":increment value2, ... }}
}
db.zips.find({"city":"ALPINE"}).count()
db.zips.updateMany({"city":"ALPINE"},{"$inc":{"pop":10}})다음 명령어들을 사용한 결과이다.
matchedCount / modifiedCount는 명령어에 들어가는 쿼리문 2개에 대한 응답 부분으로,
matchedCount는 첫 번째 인자로 들어간 조건을 충족하는 도큐먼트의 수,
modifiedCount는 두 번째 인자로 들어간 업데이트 연산자 $inc로 인해 수정된 도큐먼트의 수를 의미한다.
→ 두 부분이 동일한 값으로 출력된 것을 보아 pop 필드가 성공적으로 업데이트된 것을 확인할 수 있다.

db.zips.find({"zip":"12534"}).pretty()
db.zips.updateOne({"zip":"12534"}, {"$set":{"pop":6235}})→ $set 연산자를 사용하여 바꾸고 싶은 값을 pop 필드에 작성하면 지정한 값으로 바뀐다.
→ $set 연산자를 사용하면 주어진 필드에 지정된 값을 업데이트한다.
✷ 필드를 잘못 작성한 경우, 기존에 없는 이름인 경우라면 잘못 작성된 필드가 그대로 추가된다.
4번 배열 연산자 참고하기
db.컬렉션이름.updateOne({업데이트 할 도큐먼트를 결정하는 조건},
{"$push":{서브 도큐먼트를 삽입할 배열 타입의 값을 가지고 있는 필드:{추가할 서브 도큐먼트}}}
④ Delete
‣ deleteOne
: 주어진 기준에 맞는 다수의 도큐먼트 중 첫 번째 도큐먼트 하나를 삭제한다.
→ 기준을 충족하는 다수의 도큐먼트가 있으면 의도하지 않은 도큐먼트가 삭제될 수 있기 때문에
_id값으로 쿼리해온 도큐먼트를 삭제하는 것이 좋은 접근법이다.

먼저 고유한 _id값을 갖는 도큐먼트를 컬렉션에 삽입한 후 deleteOne()을 사용하여 삭제한다.
deleteCount에 1이 나타나는 것을 확인할 수 있다.
✷ 특정 _id값을 이용하여 delete하고 싶을 때
db.컬렉션이름.deleteOne({"_id": ObjectId("특정 아이디 값")})그냥 특정 아이디 값만 넣어서 삭제해주었을 때는 deleteCount가 0, 지워지지 않았고
""쌍따옴표를 붙여주지 않으면 SyntaxError: Identifier directly after number. (1:29) 가 떴다.
‣ deleteMany
: 기준을 충족하는 도큐먼트가 많을 경우 다수의 도큐먼트를 삭제할 수 있다.

‣ 컬렉션을 삭제하는 방법
db.컬렉션이름.drop()
true라는 응답과 함께 삭제된 것을 확인할 수 있다.
6. Aggregation Framework
: MongoDB에서 데이터를 쿼리하는 가장 간단한 방법 중 하나.
MQL(MongoDB Query Language)을 사용하는 모든 쿼리는 여기서도 할 수 있다.
① $aggregate 문법
→ find() 문법 대신 aggregate()를 사용한다.
→ 대괄호를 이용하여 배열을 인자처럼 사용한다.
(파이프라인처럼 배열 요소의 순서대로 작업을 하기 때문에)

→ 도큐먼트를 필터링하지 않고 그룹으로 데이터를 집계하거나 데이터를 수정할 수 있다.
→ 데이터 찾기 및 프로젝션 없이 작업을 수행 / 계산할 수 있다.
⇒ 해당 쿼리에선 파이프라인 작업 순서대로 amenities 배열에 Wifi가 포함되는 도큐먼트를 찾기 위해
$match 연산자를 사용하고 그렇게 찾은 도큐먼트들을 $project 연산자를 사용하여 price와 address 필드만 Projection.
✷ 파이프라인

→ 각각의 처리 작업은 우리가 나열한 배열의 순서에 의해 결정한다.
마지막으로 변환된 데이터가 파이프라인의 끝에 나타난다.

① $match
: 특정 조건에 맞지 않는 필드 값이 파이프라인의 다음 단계를 통과하지 못하도록 하는 필터 역할을 한다.
② $project
: 각 도큐먼트에서 특정 조건이 아닌 모든 필드를 필터링하는 단계.
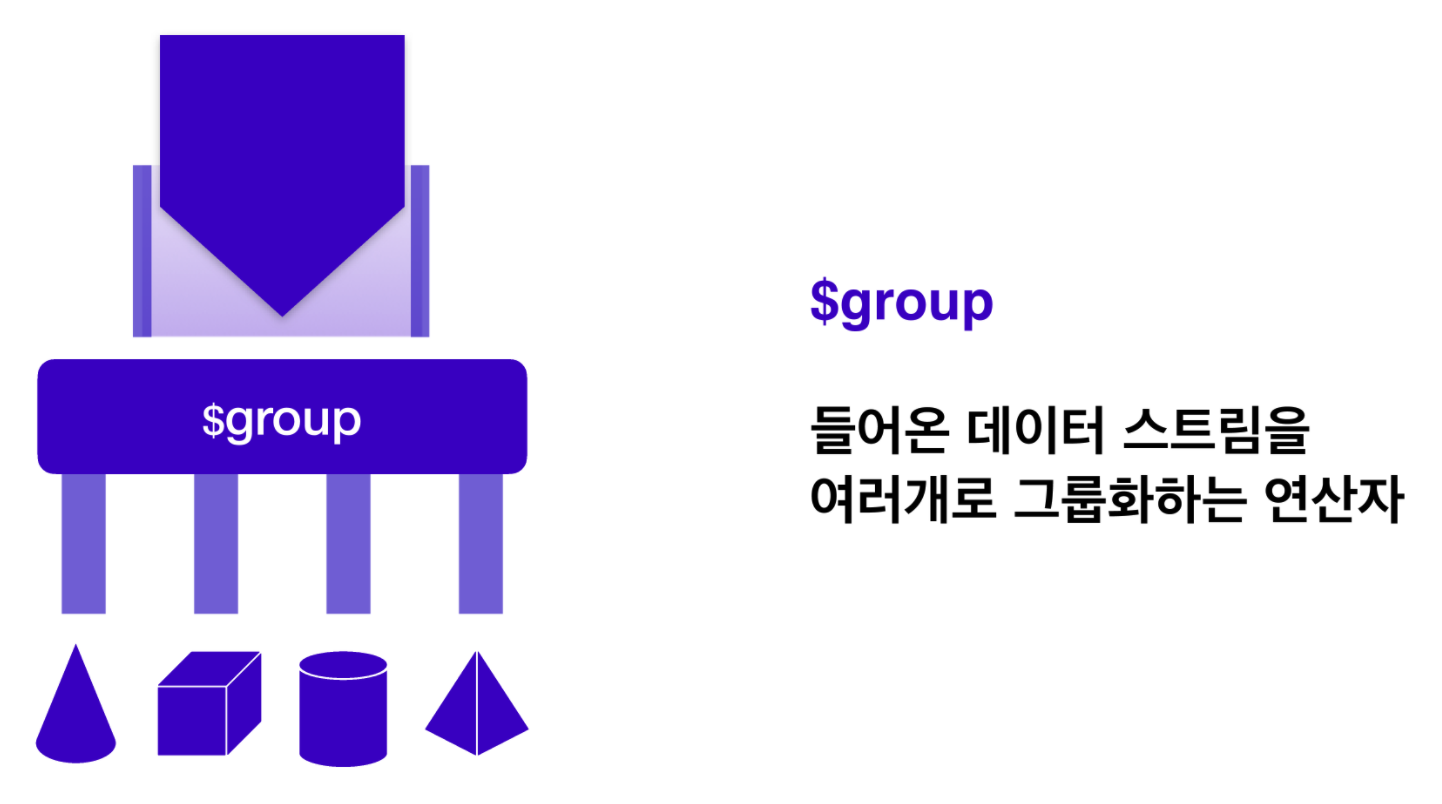
③ $group
: 들어온 데이터를 갖고 여러 개의 개별 저장소로 빨아들여 그룹화하는 연산자.
⇒ Aggregation Framework에 $match 등과 같은 필터링 단계가 없으면
데이터 요약, 계산 및 그룹화를 수행할 때 원본 데이터를 수정하지 않는다

→ 필더링 단계가 없이 원본 데이터를 바로 받아오는 경우, 원본 데이터를 수정하지 않는다.
→ 필터링 단계가 있을 때는 원본 데이터 대신 파이프라인의 이전 단계에서 가져온 데이터로 작업한다.
db.컬렉션이름.aggregate([
{$project:{"address":1, "_id":0}},
{$group: {_id: "$address.country", "count":"{"$sum":1}}}
])$project로 address필드만 쿼리한 다음
$group 연산자를 이용해 address.country값으로 데이터를 그룹화한다.
파이프라인의 첫 번째 단계에서 생성된 도큐먼트에 대해 count 필드를 만들고,
그다음 두 번째 인자에서 $sum 연산자를 사용하여 각 그룹으로 들어오는 각 도큐먼트에 대해 1씩 추가한다.

'기술개념정리(in Javascript)' 카테고리의 다른 글
| 220316 D+60 HTTPS, Hashing, Cookie, Session, CSRF (0) | 2022.03.15 |
|---|---|
| 220315 D+59 Advanced CRUD(비교, 논리, 표현, 배열 연산자, Projection, 배열과 서브 도큐먼트 쿼리하기) (0) | 2022.03.15 |
| 220315 D+59 Atlas Cluster 생성하기 (0) | 2022.03.15 |
| node.js, npm 버전 업그레이드 & 다운그레이드 (0) | 2022.03.14 |
| 220314 D+58 ORM, Sequelize(shortly-mvc) (0) | 2022.03.13 |


