
개발하고 싶은 초심자
220315 D+59 Advanced CRUD(비교, 논리, 표현, 배열 연산자, Projection, 배열과 서브 도큐먼트 쿼리하기) 본문
220315 D+59 Advanced CRUD(비교, 논리, 표현, 배열 연산자, Projection, 배열과 서브 도큐먼트 쿼리하기)
정새얀 2022. 3. 15. 17:521. 비교 연산자
: 특정한 범위 내의 데이터를 찾을 수 있음.
‣ 기본 구문
db.컬렉션이름.find({"필드":{"operator":"value"}}).pretty()
‣ 지정된 값이 같은지(equl) 아닌지(not equal)
$eq
$ne✷ $eq는 연산자가 지정되어 있지 않은 경우 기본 연산자로 사용된다.
‣ 주어진 값보다 큰 지(greater than) 아닌지(less than)
$gt
$lt
‣ 주어진 값보다 크거나 같은지(greather than or equal to) / 작거나 같은지(less than or equal to)
$gte
$lte
2. 논리 연산자
: 데이터 검색을 보다 세분화 할 수 있음.
$and 주어진 모든 쿼리절을 충족하는 도큐먼트 반환
$or 주어진 쿼리절 하나라도 일치하면 해당 도큐먼트 반환
$nor 주어진 모든 쿼리절과 일치하지 않는 도큐먼트 반환
{"operater":"[{"statement1"}, {"statement2"} ... ]"}
연산자가 작동할 절의 배열 앞에 위치한다.
$not 주어진 쿼리와 일치하지 않는 모든 도큐먼트 반환
{"$not":{"statement"}}
단순히 뒤에 오는 조건을 부정하기 때문에 배열 구문은 필요 없음.
✷ $and는 연산자가 지정되지 않았을 때 기본 연산자로 사용된다.
참이어야 하는 여러 기준이 있는 경우 기본적으로 쿼리에 함축된다.

✷ $and는 쿼리에 동일한 연산자를 두 번 이상 포함해야 할 때 명시한다.

3. 표현 연산자
→ 쿼리 내에서 집계 표현식(Aggregation Expression)을 사용할 수 있다.
→ 변수와 조건문을 사용할 수 있다.
→ 더욱 복잡한 쿼리를 작성할 수 있고, 같은 도큐먼트 내의 필드들을 서로 비교할 수 있다.
‣ 기본 구문
{"$expr":{"expression"}}

→ $를 사용하여 각각의 도큐먼트마다 달라지는 특정 필드의 값을 변수처럼 비교할 수 있다.
4. 배열 연산자
$push
: 배열에 요소를 추가하거나
이전에 다른 유형의 값이었던 경우 해당 필드를 배열 타입의 필드로 바꿀 수 있다.
→ 배열의 마지막 위치에 엘리먼트를 넣는다.
→ 배열이 아닌 필드에 사용했을 경우 필드의 타입을 배열로 바꾼다.
→ 추가적인 연산자가 없을 때에는 지정한 쿼리와 정확히 일치하는 도큐먼트만 찾는다.
→ 배열 필드를 쿼리할 때는 배열 요소의 순서는 중요하다.
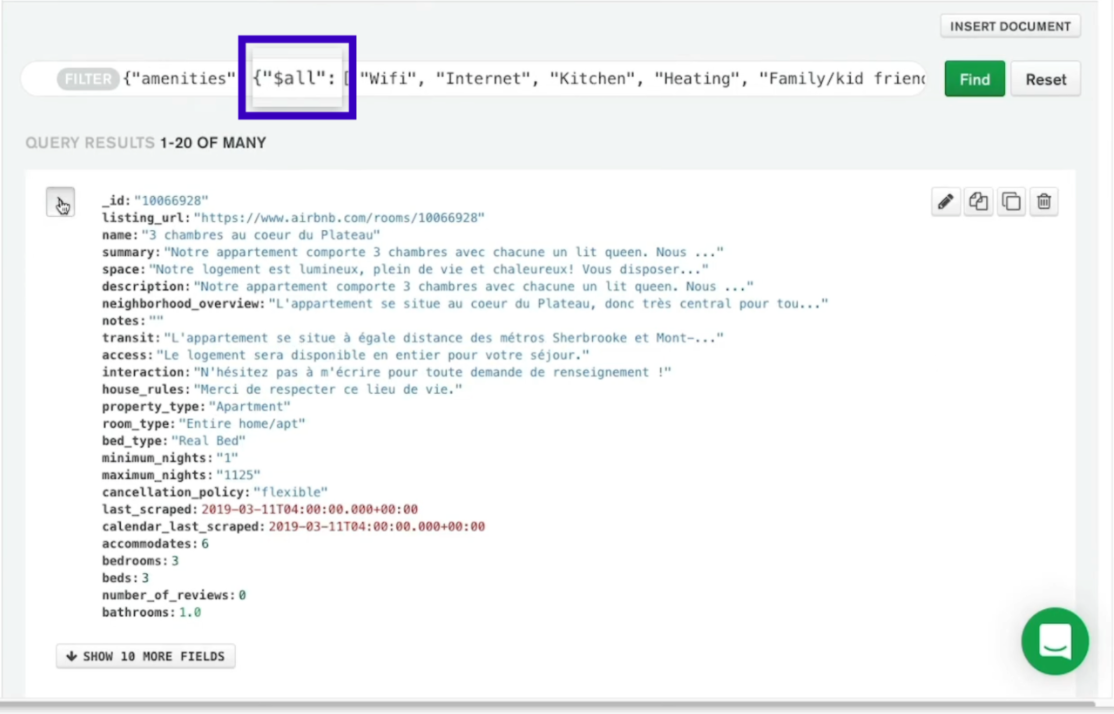
$all
{"array field":{"$all":["array"]}}→ 배열 필드에 지정한 요소가 있는 모든 도큐먼트들을 반환한다.
→ 배열의 요소와 순서 상관없이 지정된 요소가 포함된 모든 도큐먼트를 찾을 수 있다.
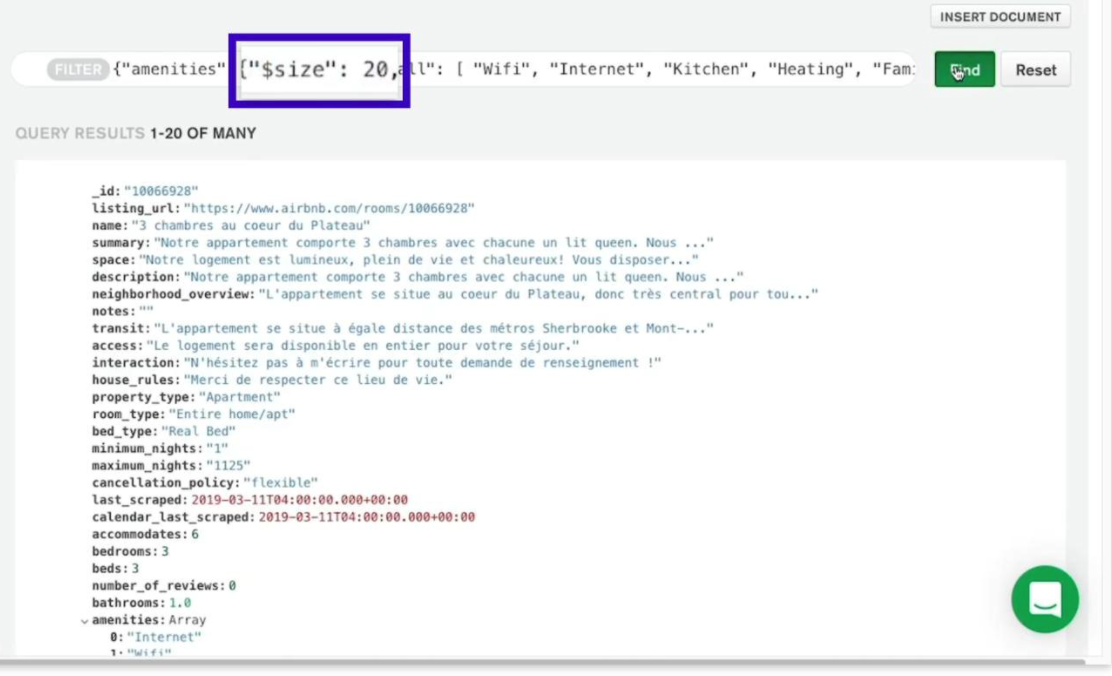
$size
{"array field":{"$size":number}}→ 지정된 배열 필드가 주어진 길이와 정확히 일치하는 모든 도큐먼트들이 있는 커서를 반환한다.
✷ cursor는 find 메소드를 실행해서 얻어낸 결과의 집합을 말한다.

5. 배열과 서브 도큐먼트 쿼리하기

→ 컬렉션의 각 도큐먼트에는 "start station location"과 "end station location"이라는 두 개의 필드가 있고,
각 필드에는 서브 도큐먼트(중첩된 도큐먼트)가 있다.

"start station location.type"으로 작성하면 start station location 도큐먼트의 type 필드에 쉽게 접근할 수 있다.
따라서 type이 Point인 도큐먼트가 결과로 반환된 것을 볼 수 있다.

모든 도큐먼트는 start station location 필드의 type 필드의 값으로 Point를 가지고 있다.
그리고 우리는 findOne을 사용했으므로 하나의 도큐먼트만 가져왔다.
start station location이라는 도큐먼트의 최상위 필드에는 서브 도큐먼트인 객체가 있다.
이 서브 도큐먼트에는 type과 coordinates라는 두 개의 필드가 있다.
두 필드의 값을 얻으려면 점 표기법을 사용해야 한다.
서브 도큐먼트의 필드 이름은 최상위 필드 뒤 점으로 구분되며 전체 내용이 따옴표로 묶여 있다.
이 표기법은 도큐먼트에서 필요한 만큼 깊이 들어가는 데 사용할 수 있다.
db.collection 역시 점을 이용하여 두 객체를 구분해 데이터베이스에서 컬렉션으로 이동한다는 것을 알 수 있다.
따라서 값으로 도큐먼트가 있는 필드가 있고 해당 필드의 값으로 또 도큐먼트가 있는 경우에도 점 표기법을 사용하여
해당 계층에서 도큐먼트 자체가 아닌 필드의 값을 가져올 수 있다.

relationships 배열의 첫 번째 요소에 마크 주커버그가 있을 것이라고 가정하고
배열의 첫 번째 요소에서만 서브 도큐먼트를 찾아본다.
배열의 위치를 찾고 있지만 Dot notation을 사용하여 relationships 배열의 첫 번째를 확인한다.
대부분의 프로그래밍 언어 및 데이터 구조의 배열 요소가 0부터 시작하는 것처럼
MongoDB도 첫 번째 요소는 위치 0에 있다.
그다음 person 필드의 값에서도 역시 점 표기법을 사용한다.
우리는 "Zuckerberg"라는 사람을 찾고 싶으므로 그의 last name을 검색한다.
마지막으로 이 컬렉션의 도큐먼트가 너무 크기 때문에 도큐먼트,
즉 회사의 name 필드 값만 가져오기 위해 name에 대한 프로젝션을 추가한다.

last name을 first name으로 변경하고 Zuckerberg를 Mark로 변경한 다음
이 요소의 title에 CEO 문자열이 포함되는 조건을 추가한다.

모든 도큐먼트에서 배열의 첫 번째 요소만이 아닌 배열 요소 전체를 검색한다.
이 사람이 아직 회사에 있는지를 확인할 수 있는 is past라는 필드가 있다.
만약 그 사람이 회사를 떠났다면 그 값은 true여야 하고,
배열 요소의 person 필드 아래에 있는 first name 필드 값은 Mark여야 한다.
편리한 elemMatch 연산자를 사용해 모든 배열 요소를 살펴보고 조건과 일치하는지 알 수 있다.
이 경우 find 명령은 이전 두 개의 쿼리보다 훨씬 짧아진다.
'기술개념정리(in Javascript)' 카테고리의 다른 글
| 220317(18) D+61(62) Token, OAuth (0) | 2022.03.16 |
|---|---|
| 220316 D+60 HTTPS, Hashing, Cookie, Session, CSRF (0) | 2022.03.15 |
| 220315 D+59 MongoDB(Basic, CRUD), Aggregation Framework (0) | 2022.03.15 |
| 220315 D+59 Atlas Cluster 생성하기 (0) | 2022.03.15 |
| node.js, npm 버전 업그레이드 & 다운그레이드 (0) | 2022.03.14 |



